The ANalysis Of Frequency datA (ANOFA) is a framework for analyzing frequencies (a.k.a. counts) of classification data. This framework is very similar to the well-known ANOVA and uses the same general approach. It allows analyzing main effects and _interaction effects_It also allow analyzing simple effects (in case of interactions) as well as orthogonal contrats. Further, ANOFA makes it easy to generate frequency plots which includes confidence intervals, and to compute eta-square as a measure of effect size. Finally, power planning is easy within ANOFA.
A basic example
As an example, suppose that you observe a class of primary school students, trying to ascertain the different sorts of behaviors. You might use an obsrevation grid where, for every kid observed, you check various things, such as
| Student Id: A | |
|---|---|
| Gender: | Boy [x] Girl [ ] Other [ ] |
| Type of interplay: | Play alone [x] Play in group [ ] Harrass others [ ] Shout against other [ ] |
| etc. |
This grid categorizes the participants according to two factors,
Gender, and TypeOfInterplay.
From these observations, one may wish to know if gender is more related to one type of interplay. Alternatively, genders could be evenly spread across types of interplay. In the second case, there is no interaction between the factors.
Some data
Once collected through observations, the data can be formated in one of many ways (see the vignette Data formats). The raw format could look like
| Id | boy | girl | other | alone | in-group | harass | shout |
|---|---|---|---|---|---|---|---|
| A | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| B | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| C | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| D | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| … |
For a more compact representation, the data could be
compiled into a table with all the combination of gender \(\times\) types of interplay, hence
resulting in 12 cells. The results (totally ficticious) looks like
(assuming that they are stored in a data.frame named
dta):
dta## Gender TypeOfInterplay Freq
## 1 boy alone 10
## 2 girl alone 55
## 3 other alone 13
## 4 boy ingroup 54
## 5 girl ingroup 25
## 6 other ingroup 11
## 7 boy harrass 8
## 8 girl harrass 44
## 9 other harrass 8
## 10 boy shout 12
## 11 girl shout 47
## 12 other shout 13for a grand total of 300 childs observed.
Analyzing the data
The frequencies can be analyzed using the Analysis of Frequency Data (ANOFA) framework (Laurencelle & Cousineau, 2023). This framework only assumes that the population is multinomial (which means that the population has certain probabilities for each cell). The relevant test statistic is a \(G\) statistic, whose significance is assessed using a chi-square table.
ANOFA works pretty much the same as an ANOFA except that instead of looking at the means in each cell, its examines the count of observations in each cell.
To run an analysis of the data frame dta, simply
use:
This is it. The formula indicates that the counts are stored in
column Freq and that the factors are Gender
and TypeOfInterplay, each stored in its own column. (if
your data are organized differently, see Data
formats).
At this point, you might want a plot showing the counts on the vertical axis:
anofaPlot(w) 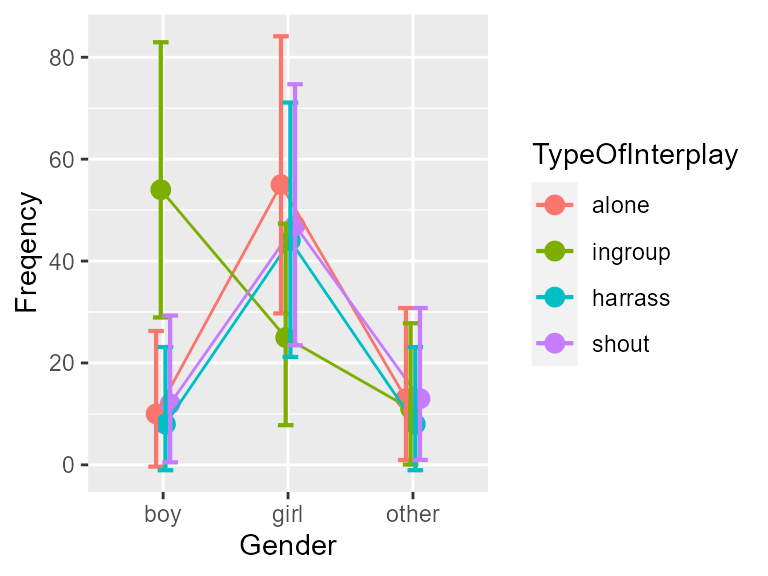
Figure 1. The frequencies of the ficticious data as a function of Gender and Type of Interplay. Error bars show difference-adjusted 95% confidence intervals.
We can note a strong interaction, the ingroup activity
not being distributed the same as a function of Gender. To
confirm the interaction, let’s look at the ANOFA table:
summary(w)## G df Gcorrected pvalue etasq
## Total 154.520 11 NA NA NA
## Gender 82.324 2 82.141 0.00000 0.21532
## TypeOfInterplay 6.281 3 6.263 0.09948 0.02051
## Gender:TypeOfInterplay 65.916 6 65.055 0.00000 0.33996Indeed, the interaction (last line) is significant (\(G(6) = 65.92\), \(p < .001\)). The \(G\) statistics is corrected for small sample but the correction is typically small (as seen in the fourth column).
We might want to examine whether the frequencies of interplay are
equivalent separately for each Gender, even though
examination of the plot suggest that it is only the case for the
other gender. This is achieved with an analysis of the
simple effects of TypeOfInterplay within each
level of Gender:
e <- emFrequencies(w, Freq ~ TypeOfInterplay | Gender)
summary(e)## G df Gcorrected pvalue etasq
## TypeOfInterplay | boy 58.291 3 58.130 0.000000 0.40966
## TypeOfInterplay | girl 12.337 3 12.303 0.002131 0.06729
## TypeOfInterplay | other 1.569 3 1.565 0.457342 0.03369As seen, for boys and girls, the type of interplay differ
significantly (both \(p < .002\));
for others, as expected from the plot, this is not the case
(\(G(3) = 1.57\), \(p = 0.46\)).
If really, you need to confirm that the major difference is caused by
the ingroup type of activity (in these ficticious data),
you could follow-up with a contrast analysis. We might compare
alone to harass, both to shout,
and finally the three of them to ingroup.
f <- contrastFrequencies(e, list(
"alone vs. harass " = c(-1, 0, +1, 0 ),
"(alone & harass) vs. shout " = c(-1/2, 0, -1/2, +1 ),
"(alone & harass & shout) vs. in-group" = c(-1/3, +1, -1/3, -1/3)
))
summary(f)## G df Gcorrected pvalue
## alone vs. harass | boy 0.222682 1 0.220494 0.638664
## (alone & harass) vs. shout | boy 0.582739 1 0.577014 0.447485
## (alone & harass & shout) vs. in-group | boy 57.485613 1 56.920921 0.000000
## alone vs. harass | girl 1.224750 1 1.218810 0.269594
## (alone & harass) vs. shout | girl 0.086118 1 0.085700 0.769716
## (alone & harass & shout) vs. in-group | girl 11.025872 1 10.972400 0.000925
## alone vs. harass | other 1.201987 1 1.180133 0.277329
## (alone & harass) vs. shout | other 0.359564 1 0.353027 0.552405
## (alone & harass & shout) vs. in-group | other 0.007444 1 0.007309 0.931869Because the contrast analysis is based on the simple effects within
Gender (variable e), we get three contrasts
for each gender. As seen, for boys, in-group is the sole
condition triggering the difference. Same for girls. Finally, there are
no difference for the last group.
Additivity of the decomposition (optional)
The main advandage of ANOFA is that all the decomposition are entirely additive.
If, for example, you sum the \(G\)s and degrees of freedom of the contrasts, with e.g.,
## [1] 72.19677
## [1] 9you get exacly the same as the simple effects:
## [1] 72.19677
## [1] 9which is also the same as the main analysis done first, adding the
main effect of TypeOfInterplay and its interaction with
Gender (lines 3 and 4):
## [1] 72.19677
## [1] 9In other words, the decompositions preserved all the information available. This is the defining characteristic of ANOFA.