What is an Analysis of Proportions using the Anscombe Transform?
Source:vignettes/A-WhatIsANOPA.Rmd
A-WhatIsANOPA.RmdThe ANalysis Of Proportion using the Anscombe transform (ANOPA) is a framework for analyzing proportions (often written as percentages) across groups or across measurements. This framework is similar to the well-known ANOVA and uses the same general approach. It allows analyzing main effects and interaction effects. It also allow analyzing simple effects (in case of interactions) as well as orthogonal contrats and post-hoc tests. Further, ANOPA makes it easy to generate proportion plots which includes confidence intervals, and to compute eta-square as a measure of effect size. Finally, power planning is easy within ANOPA.
A basic example
As an example, suppose a study where three groups of participants are tested on their ability to have an illumination according to the nature of a distracting task. This example is found in .
The data can be given with 1s for those participants who experienced an illumination and with 0s for those who didn’t. Thus, a table having one line per participant giving the observations would look like:
| Condition of distraction | Illumination? |
|---|---|
| Doing Crosswords | 1 |
| Doing Crosswords | 0 |
| Doing Crosswords | 0 |
| … | … |
| Doing Crosswords | 1 |
| Solving Sudokus | 0 |
| Solving Sudokus | 1 |
| Solving Sudokus | 1 |
| … | … |
| Solving Sudokus | 0 |
| Performing chants | 0 |
| Performing chants | 1 |
| … | … |
| Performing chants | 0 |
| Controlling breath | 1 |
| Controlling breath | 1 |
| … | … |
| Controlling breath | 0 |
This long table can easily be reduced by “compiling” the results, that is, by counting the number of participants per group who experienced and illumination. Because the group sizes may not be equal, counting the number of participants in each group is also needed. We would then observe
| Condition of distraction | Number of illumination | Group size |
|---|---|---|
| Doing Crosswords | 10 | 30 |
| Solving Sudokus | 14 | 22 |
| Performing chants | 7 | 18 |
| Controlling breath | 5 | 27 |
| :—————- | ————————- | ————————— |
From these data, we may wonder if the four interventions are equally likely to result in an illumination. Transforming the number of illumination in percentage provide some indications that this may not be the case:
| Condition of distraction | Percentage of illumination |
|---|---|
| Doing Crosswords | 33.3% |
| Solving Sudokus | 63.6% |
| Performing chants | 38.9% |
| Controlling breath | 18.5% |
| :—————- | ————————— |
In all likelihood, solving Sudokus puts participants in a better mental disposition to have an illumination whereas controlling ones’ breath might be the worst intervention to favor illuminations.
But how can we be confident of the reliability of this observation? The sample is fairly large (total sample size of 97) and the effect seems important (percentages ranging from 18 to 64% are not showing trivially small differences) so that we can expect decent statistical power.
How do we proceed to formally test this? This is the purpose of ANOPA.
The rational behind the test (optional)
ANOPA makes the following operations transparent. Hence, if you are not interested in the internals of an ANOPA, you can just skip to the next section.
The general idea is to have an ANOVA-like procedure to analyse proportions. One critical assumption in ANOVA is that the variances are homogeneous, that is, constant across conditions. Sadly, this is not the case of proportions. Indeed, proportions close to 0% or close to 100% (floor and ceiling) are obtained when in the population, the true proportions are small (or large; we consider the former scenario hereafter, but the rational is symmetrical for large population proportions). When this is the case, there is very little room to observe in a sample a proportion much deviant from the population proportion. For example if the population proportion is, say, 5%, then in a sample of 20 participants, you cannot expect to observe frequencies very far from 5%. A contrario, if the population true proportion is 50%, then on a sample of 20 participants, a larger range of observed proportions are possible. This simple illustration shows that the possible variance in the scores are not homogeneous: few variance is expected for extreme proportions and more variance is expected for proportions in the middle of the range (near 50%).
Because the purpose of the analysis is to see if the proportions might be different, it means that we envision that they occupy some range, and therefore, we cannot maintain that variances are homogeneous. We therefore need a “variance-stabilizing” approach.
The purpose of the Anscombe transform (an extension of the arcsine transform) is precisely this: replace proportions with an alternate measure which has the same expected variance irrespective of the population variance . Anscombe showed that the variance of this transformed proportions is a constant determined only by the number of observations. Thus, we have a variance- stabilizing transformation. As an added bonus, not only are the variances stabilized, but we actually know their values. Hence, it is no longer necessary to estimate the “error term” in an ANOVA. As the error term is known, the denominator of the ANOVA is calculated without degrees of freedom (we set them to to denote this).
Recent works (see last section) confirms that this transformation is actually the most accurate approximation we know to this day and that there is very little room to find a more accurate transformation.
Analyzing the data
The dataset above can be found in a compiled format in the dataframe
ArticleExample1:
ArticleExample1## DistractingTask nSuccess nParticipants
## 1 Crosswords 10 30
## 2 Sudoku 14 22
## 3 Chants 7 18
## 4 Breath 5 27(there are alternate formats for the data discussed in the vignette
DataFormatsForProportions.
As seen the group labels are given in column
DistractingTask whereas the observations are described in
nSuccess (the number of 1s) and nParticipants
(the number of observations, i.e., the number of 0s and 1s). To see the
results as proportions, divide the number of succcess by the number of
observations, for example
ArticleExample1$nSuccess / ArticleExample1$nParticipants## [1] 0.3333333 0.6363636 0.3888889 0.1851852(multiply by 100 to have percentages rather than proportions.)
The analysis is very simply triggered by the following
w <- anopa( {nSuccess; nParticipants} ~ DistractingTask, ArticleExample1)The first argument is a formula which describes how the data are
presented (before the ~) and what are the factors in the design (after
the ~). Here, because the observations are actually described over two
columns (the number of 1s and the total number of participants in each
group), we use the {s;n} notation which can be read as “s
over n” (note the curly braces and the semi-colon which is not standard
notation in R). The second argument is the data frame, here in compiled
form.
You are done!
Please start (always start) with a plot.
anopaPlot(w) 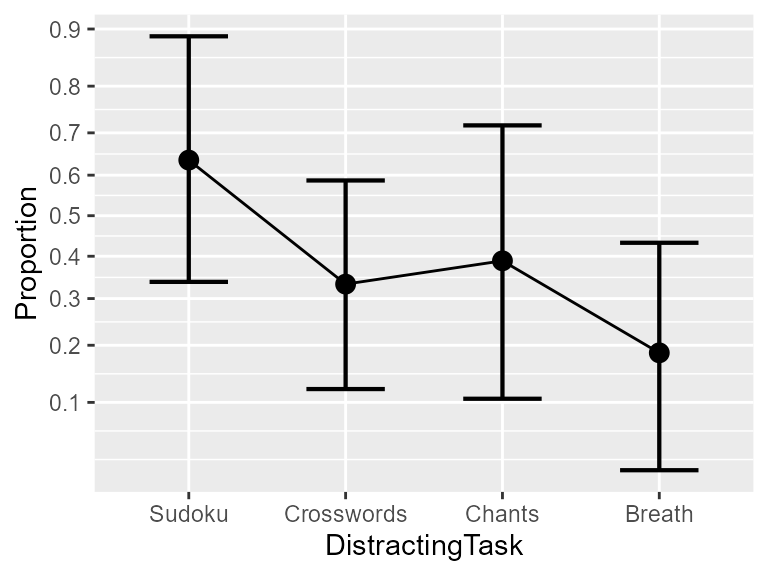
Figure 1. The proportion of illumination as a function of the distracting task. Error bars show difference-adjusted 95% confidence intervals.
This plot shows confidence intervals that are “difference adjusted” . Such confidence intervals allows comparing between-conditions using the golden rule: if a result is not included in the confidence interval of another score, then the two conditions are likely significantly different. In the above plot, we see that the Breath condition is not included in the Sudoku condition, so that we can expect these two conditions to differ significantly, and as such, the ANOPA to show a significant rejection of the null hypothesis that all the proportion are equal.
The ANOPA table is obtained as usual with summary() or
summarize():
summarize(w)## MS df F p correction Fcorr pvalcorr
## DistractingTask 0.036803 3 3.512416 0.01451 1.035704 3.391331 0.017144
## Error 0.010478 Infor if you just want the corrected statistics (recommended), with
corrected(w)## MS df F correction Fcorr pvalcorr
## DistractingTask 0.036803 3 3.512416 1.035704 3.391331 0.017144
## Error 0.010478 InfAs seen, the (uncorrected) effect of the Distracting Task is
significant
(,
).
Because for small samples, the F distribution is biased up, an
adjusted version can be consulted (last three columns). The results is
nearly the same here
(,
)
because this sample is far from being small. The correction is obtained
with Williams’ method and reduces the F by 3.6% (column
correction shows 1.0357).
Post-hoc test
The proportions can be further analyzed using a post-hoc test to determine which pairs of distracting tasks have different proportions of illumination. To that end, we use Tukey’s Honestly Significant Difference (HSD) procedure.
# posthocProportions( w ) ## not yet bundled in the libraryAs seen, the Breath condition differs significantly from the Sudoku condition. Also the Crosswords condition also differs from the Sudoku conditions. These are the only two conditions for which a difference seems statistically warranted.
This is it. Enjoy!
The vignette ArringtonExample examines a real dataset where more than one factor is present.
A common confusion
A common confusion with regards to proportions is to believe that mean proportion is a proportion. In Warton and Hui 2011, we also have median proportions. All these expresses confusion as to what a proportion is.
A proportion must be based on 1s and 0s. Thus, if a group’s score is a proportion, it means that all the members of that group have been observed once, and were coded as 0 or 1.
If you have multiple observations per subject, and if the group’s score is the mean of the subject’s proportion, then you are in an un-pure scenario: your primary data (the subjects proportions) are not 0 or 1 and therefore, analyzing this situation cannot be done with ANOPA.
If, on the other hand, you consider that the repeated measurements of each participant is a factor, then you can analyze the results with ANOPA assuming that the factor “repetition of the measurement” is a within-subject factor.
In the worst-case situation, if the participants were measured multiple times, but you do not have access to the individual measurements, then you may treat the proportions as being means and run a standard ANOVA. However, keep in mind that this approach is only warranted if you have a lot of measurements (owing to the central limit theorem). With just a handful of measurements, well, no one can help you…
Why infinite degrees of freedom? (optional)
For some, this notation may seems bizarre, or arbitrary. However, it is formally an exact notation. An equivalent notation relates the tests and the tests. As is well-known, the test is used when the population variance is unknown and estimated from the sample’s variance. In this test, this variance can be seen as the “error term”. However, when the population variance is known, we can use this information and the test then becomes a test. Yet, the distribution (and the critical value of this test) is identical to a standardized Normal distribution when the degrees of freedom in the distribution tends to infinity. In other words, a test is the same as a test when there is no uncertainty in the error term. And when there is no uncertainty in the error term, we can replace the degrees of freedom with infinity.
This rationale is the same in the ANOPA which explains why we note the denominator’s degree of freedom with infinity.
Why the arcsine transform? (optional)
This transformation may seem quite arbitrary. Its origin shows indeed that this solution was found by a vague intuition. Fisher is the first to propose trigonometric transformations for the study of statistics in 1915. This approach was found fertile when applied to correlation testing, where the arctan transform (formally, the inverse hyperbolic tangent transformation) provided an excellent approximation (Fisher, 1921).
When Fisher considered the proportions, his first attempt was to suggest a cosine transform . Zubin later refined the approach by suggesting the arcsine transform . The basic form of the arcsine transform was further refined by Anscombe to the form we use in the ANOPA (Anscombe, 1948). Anscombe modifications, the addition of 3/8 to the number of success and 3/4 to the number of trials, led to a theoretical variance exactly equal to .
Formidable development in the early 90s showed that this transform has other important characteristics. For example, Chen (1990) and Lehman & Loh (1990) derived that this transform will either underestimate the true probability or overestimate it. More importantly, Chen showed that no other transformation is known to fluctuate less than the arcsine transform around the exact probability. This transformation is therefore the best option when analyzing proportions.
You can read more in Laurencelle & Cousineau (2023); also check Chen (1990) or Lehman & Loh (1990) for mathematical demonstrations showing the robustness of the ANOPA. Finally, Williams (1976) explains the correction factor and its purpose.